
UPDATE:
We've just built our free-to-use cookie compliance test. Scan your site and discover if it adheres to local privacy laws.
A few years ago, 7DOTS were approached by a global insurance broker and professional services firm who asked us to independently audit their websites to make sure they complied with data protection laws like the GDPR.
The client was a Fortune 500 company with an online portfolio comprising hundreds of websites. They were headquartered in New York, but their websites were being visited by users all over the world. This meant we had to make sure the sites were legally compliant, according to data protection law in the territory of the person using the site.
The project demanded a challenging combination of accuracy and efficiency, and as the principal Data Scientist at 7DOTS, I was tasked with devising the technical solution. Websites would need to be meticulously audited, taking into account relevant legislation, different user scenarios, and the various ways that web browsers store data. Conversely, the volume of sites meant that we needed to work quickly. This meant employing automation wherever we could, and ensuring the results were actionable and easy to understand.
Why are we doing this?
The General Data Protection Regulation (GDPR) is a vast piece of legislation that protects citizens of the EU and UK by governing how organisations collect, process, store, and use their personal data. Under the GDPR, the use of browser technologies like cookies and local storage are regulated because they can be used to collect personal data.
In addition to the GDPR, website owners also need to consider the catchily named EU Directive 2002/58/EC, or the ePrivacy directive to its mates. This directive came into force back in 2002, when it was used by EU member states to draft their own pieces of legislation. The ePrivacy directive is less ambiguous on the use of technology like cookies, specifically, organisations must obtain explicit consent from users before storing or accessing any information on their devices.
The ePrivacy Directive, along with the GDPR, is one of the strictest data protection regulations out there. At 7DOTS we often tell our clients that if you’re compliant according to the GDPR, then you’re compliant everywhere else. This is important, because it doesn’t matter where your servers are, if someone visits your site from a protected territory, you need to handle their data according to the legislation of that territory.
Website owners also need to provide clear information about the types of storage they use, and users must have the option to accept or reject them. In the case of users protected by the GDPR and the ePrivacy directive, we already know we need to get their consent before we store or access any data on their devices. That is unless the storage in question can be classified as strictly necessary, this means it’s essential for the web service to function and therefore exempt from the rules. Strictly necessary, along with functional, analytics, and advertising are typical categories that website owners use to describe the purpose of the storage they set and access on users’ devices. Naturally, this adds complexity to the auditing process because we need to undertake tests to see how the website responds to user preferences on different types of storage. For example, what happens when a user gives consent for all types of storage except advertising? Are the user’s specific preferences respected?
If you’re enjoying any of this legal talk, first of all I’d be surprised, but you should check out this article by our Demand Generation Director, Nick Williams, who goes into more detail on the requirements set out by the GDPR and the financial consequences of ignoring them.
How do we do it?
The complexity of data protection laws like the GDPR and the requirements set out by our client means we have a technical challenge on our hands, but if we summarise the exercise it looks like this:
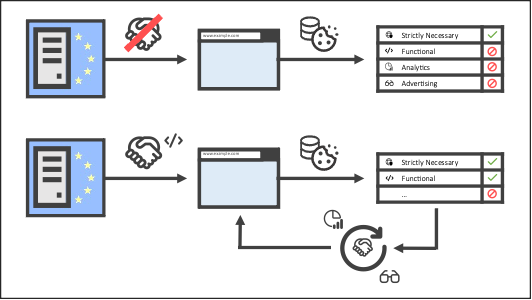
We need to undertake two types of test and both take place from a protected territory, like the EU. In the first test, we visit the website without providing any consent, if the website uses any storage apart from that classified as strictly necessary, it’s failed the test. Subsequent tests involve opting into the other storage categories, one-by-one. If anything other than the permitted type of storage is used, the website has failed the test. As before, strictly necessary storage is always allowed.
The tech stack
We had to come up with a tech solution that was reliable and fast, but the project was underway and we needed something that worked immediately. Owing to its mature ecosystem of packages, Python was the obvious choice. Specifically, we chose Selenium for browser automation and Ray for scalability. In order to manage our database of cookie classifications, we went with Django for its excellent ORM and easy-to-use admin panel.
The solution was designed to work as a CLI app, this meant we could have a working prototype sooner, and it would only be used internally, so UX wasn’t a concern. The entry point of the app takes some command line arguments, like the first page of the website you’d like to scan, the type of consent manager the website is using and the number of threads you want to use.

This command creates an instance of a “Governor” class, this class handles some setup, such as starting our Ray Actors, importing our Django models and setting up a DB connection. The app is structured using different types of Ray Actor, each playing a different role in the auditing process. Namely, the Prospector Actor which handles found URLs and allocates them to an appropriate Worker depending on their workloads. The Worker Actor is responsible for running all of our tests and controlling the Selenium WebDriver, and the number of Workers we set up is defined by the value of the `threads` argument. Finally, the Logger Actor keeps track of our known URLs and gives real-time updates at the terminal using curses.
Using Ray makes it easy to distribute our code over multiple sub-processes (or even machines) without having to be concerned with thread safety. This is critical because our Ray Actors need an up to date list of known URLs, otherwise they’ll be stepping on each other’s toes, visiting URLs that have already been scanned.
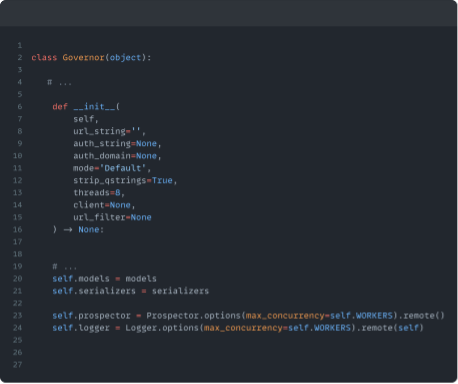
The Governor class performs all of our initial setup, importing our Django models and starting up our Ray Actors.
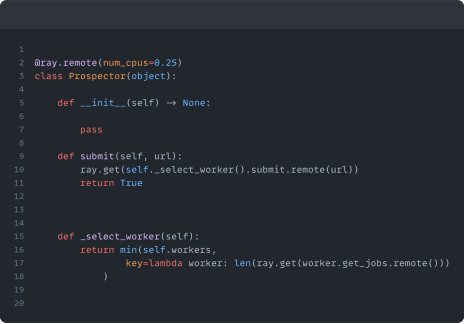
The Prospector receives found URLs and selects a Worker based on their workloads.
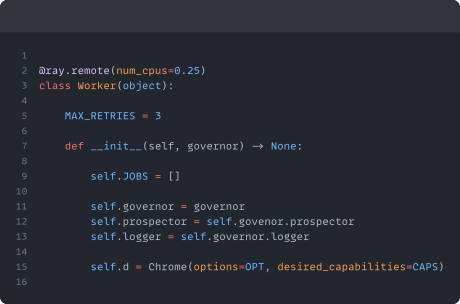
The Worker controls the Selenium WebDriver and runs all of our tests.
Running Some Tests
When we run our app from the command line, we need to specify a `mode` argument, this describes the type of Cookie Consent Manager (CCM) being used on the website we’re testing. Examples of CCMs include TrustArc, OneTrust, and CookiePro. In our database, we have a range of different CCM configurations which are records of cookies normally set by CCMs that correspond to different levels of user consent. For each test we want to undertake, we pre-set cookies that tell the CCM which type of storage we’re consenting to, or opting out of. The tests also have records of the categories of storage that, based on the CCM cookie value, we would not expect to be accessed or set.
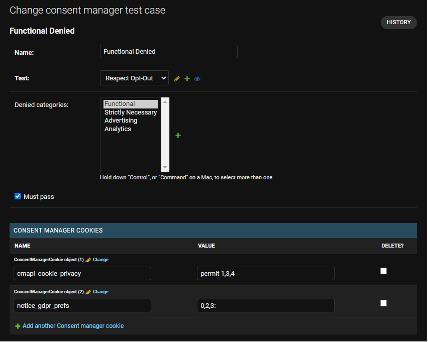
In the Django admin panel, we can easily set up our test cases. In this example, cookies have been specified that tell the CCM we’ve opted into everything except functional storage and we specify Functional as a denied category.
When we initialize our Worker Actors, they query the database for the tests they’ll need to undertake. Every time a Worker receives a URL, it runs through these tests, and for each one, it starts a fresh Chromium instance, sets the CCM cookies, and visits the URL.
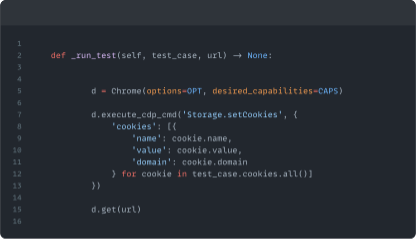
Before visiting a URL, the Worker sets the cookies that correspond to different levels of consent.
What are we looking for?
There are only a few ways that browsers physically store information on devices, and if you decide not to use browser storage, you might be employing hard-to-detect methods like device fingerprinting. This is the practice of measuring device characteristics that, when combined, begin to create a unique device profile, or fingerprint. A piece of research undertaken by the Electronic Frontier Foundation back in 2010 found that you’d need to profile 286,777 devices before you found two with the same fingerprint.
You might feel like fingerprinting is an invasion of privacy, but to decide whether it’s regulated by data protection law, we could refer to Opinion 9/2014 from the EU’s Data Protection Working Party (WP29). That’s right, opinion, and it means just that. Opinions are non-legally binding statements made by EU institutions, and this one is about the applicability of the ePrivacy Directive to device fingerprinting. However, it falls short of saying the law applies in all cases, instead only those that involve “the gaining of access to, or the storing of, information on the user’s terminal device” – so we’re talking about device storage again!
In essence, I’m always hesitant to say “this website is compliant” because not only is it very difficult to detect every tracking method, it’s even harder to determine whether a given method is prohibited by law. For this reason, when we undertake our tests, we only base our opinion on actual storage and the access thereto. To that end, our focus is on the most common types of storage used by browsers: cookies (of course); and their younger counterparts, HTML web storage (local and session).
How do we find them?
Once our Workers have visited a URL and set the preference cookies for the test were doing, we need to make a record of any storage the website set or accessed. In the case of cookies, we can use Selenium’s integration with the Chrome DevTools Protocol (CDP). The CDP is a powerful protocol that exposes a rich set of APIs, and some of these allow us to programmatically gather data from the browser. To make a record of the cookies set by the website we need to use the CDP storage API.
The storage API lets us create a record of all the cookies set after we visited the URL we are testing.
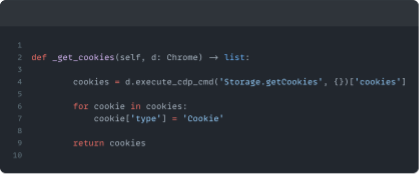
We’ll use a similar approach for HTML web storage and once we’ve done that, we’ll make a record of the test we undertook, and the storage used during that test.
Interpreting the results
Every time we visited a URL we undertook a number of tests, and for each of those tests we made a record of the associated storage. As I’m sure you can imagine, that’s a lot of data, especially for large sites. Being conscious of performance, and to make dealing with the data easier, I opted to store all of our results in a Pandas DataFrame. The DataFrame provides a range of methods that are going to be invaluable when interpreting the results of our audit.
Each row of our DataFrame is a record of a test, a website URL, and an item of storage that we found. We also have a large database of known storage, each classified by their purpose. Our database uses a relational model, where our known storage items are classified by their relation to storage categories. These categories are also related to the test cases, the categories that we specified as denied for a given test.
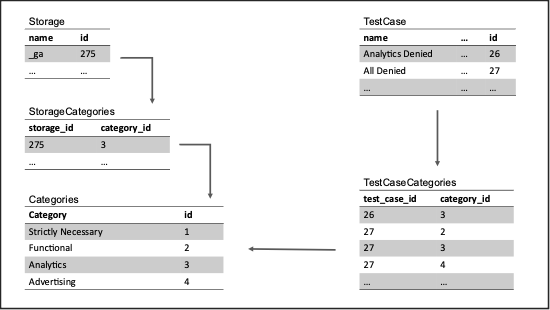
The relational database model means that our cookie categories are related to both items of storage as classification categories, and to test cases as denied categories.
Before we can pull results from our DataFrame, we need to assign the contained storage instances categories using the classifications in our database. Once our storage is classified, we can leverage the relational model to elegantly find audit failures. We simply identify any rows in our DataFrame where the denied category is equal to the category of the found storage, any overlap means the website has failed.
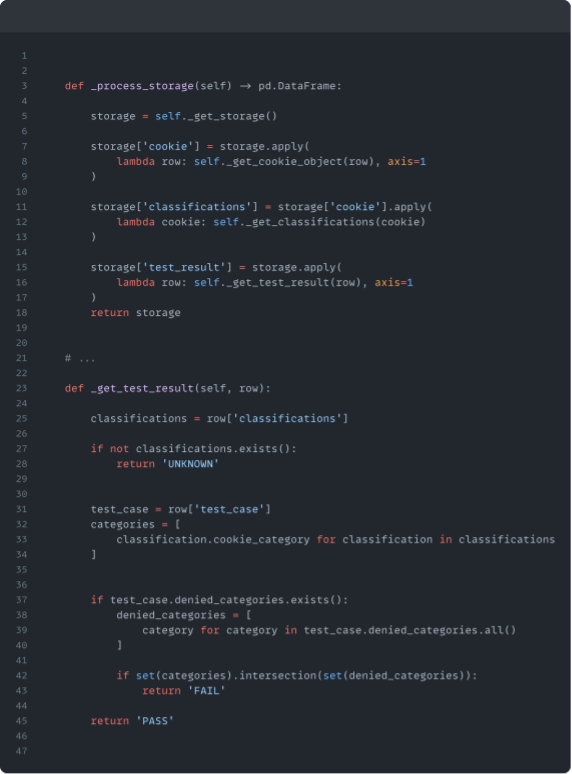
Using the DataFrame `apply()` method allows us to efficiently identify rows where there is an intersection between cookie categories and test case denied categories, and therefore failures.
At this point we have a DataFrame of storage instances that failed our tests, along with the tests they failed. Now it’s trivial to use the DataFrame `groupby` method to summarise our data into an actionable report, showing each found storage instance, an example of a URL where it may have failed, the results of the tests it was subject to, and its resultant compliance status.
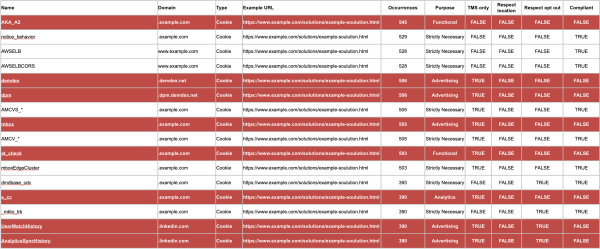
Our clients receive a report which is invaluable during the remediation process.
This is a technique that 7DOTS have perfected over years of refinement, but it doesn’t stop at sending our clients an audit. The audit only marks the beginning of an iterative remediation process, which involves the classification of cookies by our clients, and the re-configuration of tag managers by the experts at 7DOTS. The 7DOTS Intelligence Team also work with our clients to implement more complex code-based fixes, including cases where storage is set by iframes, or scripts that can’t be loaded using tag managers. Once fixes have been implemented, and reclassifications made, audits are repeated until the website achieves full compliance.
Common Pitfalls
Using `document.cookie`
A naïve implementation of our application might involve asking Selenium to execute some JavaScript to evaluate `document.cookie`, but this approach is problematic because it doesn’t account for HTTP-only cookies. The HTTP-only attribute is a security feature which prevents cookies being read by client-side JavaScript. Cookies with this attribute are invisible to JavaScript, so if we used `document.cookie` they wouldn’t be included in our audit.
It’s therefore crucial to evaluate cookies using the Chrome DevTools Protocol (CDP), specifically we use the `Storage.getCookies` command to retrieve all the cookies the browser knows about.
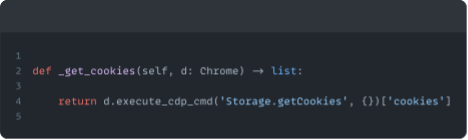
The `Storage.getCookies` command returns a list of all the cookies set during the test we performed, including HTTP-only.
Deleting Cookies retrospectively
In our website-auditing experience, it’s not uncommon for website owners to delete cookies after they’ve been set, but retrospectively deleting cookies does not a compliant website make! If you set storage without getting consent from the user first, deleting them afterwards isn’t going to help. This type of compliance breach can be hard to detect too, especially when cookies are deleted shortly after page load. To measure the instantaneous setting and deleting of cookies, we employ the Cookie Store API. This API has limited browser support, but if you’re running your tests from a supported browser (e.g. Chrome) then you can listen for the Cookie Store’s `CookieChangeEvent` to detect when any cookie changes occur.
Being too bot-like
Sometimes a website will outright block you because you look like a bot, in other cases its third-party scripts will refuse to load. In website auditing, the latter is arguably worse because, to the auditor, it appears that the website is compliant. In fact, we’re in a sort of Schrödinger’s Cookie situation, where the act of observing the cookies has prevented them from appearing!
In either case, the best way to overcome the problem is to ensure you look as human as possible. We can do this by setting some Selenium flags, along with rotating attributes like user agent or viewport size.
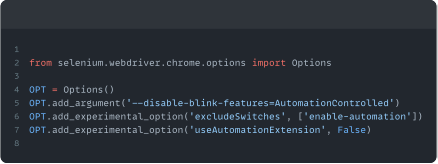
We set some Selenium options, and importantly the `--disable-blink-features` argument, which removes the `navigator.webdriver` property, a huge bot giveaway.
Thinking you’re done, when you’re not
One of the biggest challenges you’ll face when building your own web crawler is avoiding race conditions. If you’re not careful with thread safety, you’ll end up scraping URLs you’ve already visited, or you’ll think you’re done when you’re not. The latter is problematic because we can end up checking for done-ness before a Worker has finished submitting its found URLs to our Prospector. To avoid this situation we can invoke Ray’s `wait()` method, to ensure Workers have submitted at least one of their URLs before we check if we’re done. This prevents a situation where all Workers are jobless, so in effect we’ve met the done criteria, but we have URLs waiting to be allocated to our worker.
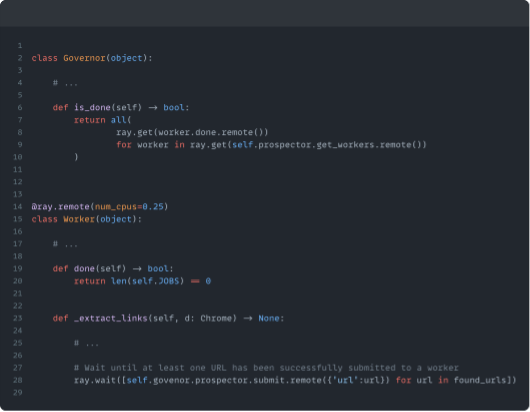
`ray.wait()` is blocking until at least one remote call has succeeded, this means that our Worker’s `done()` method won’t return when we’re submitting URLs unless we’ve submitted at least one of them successfully .
